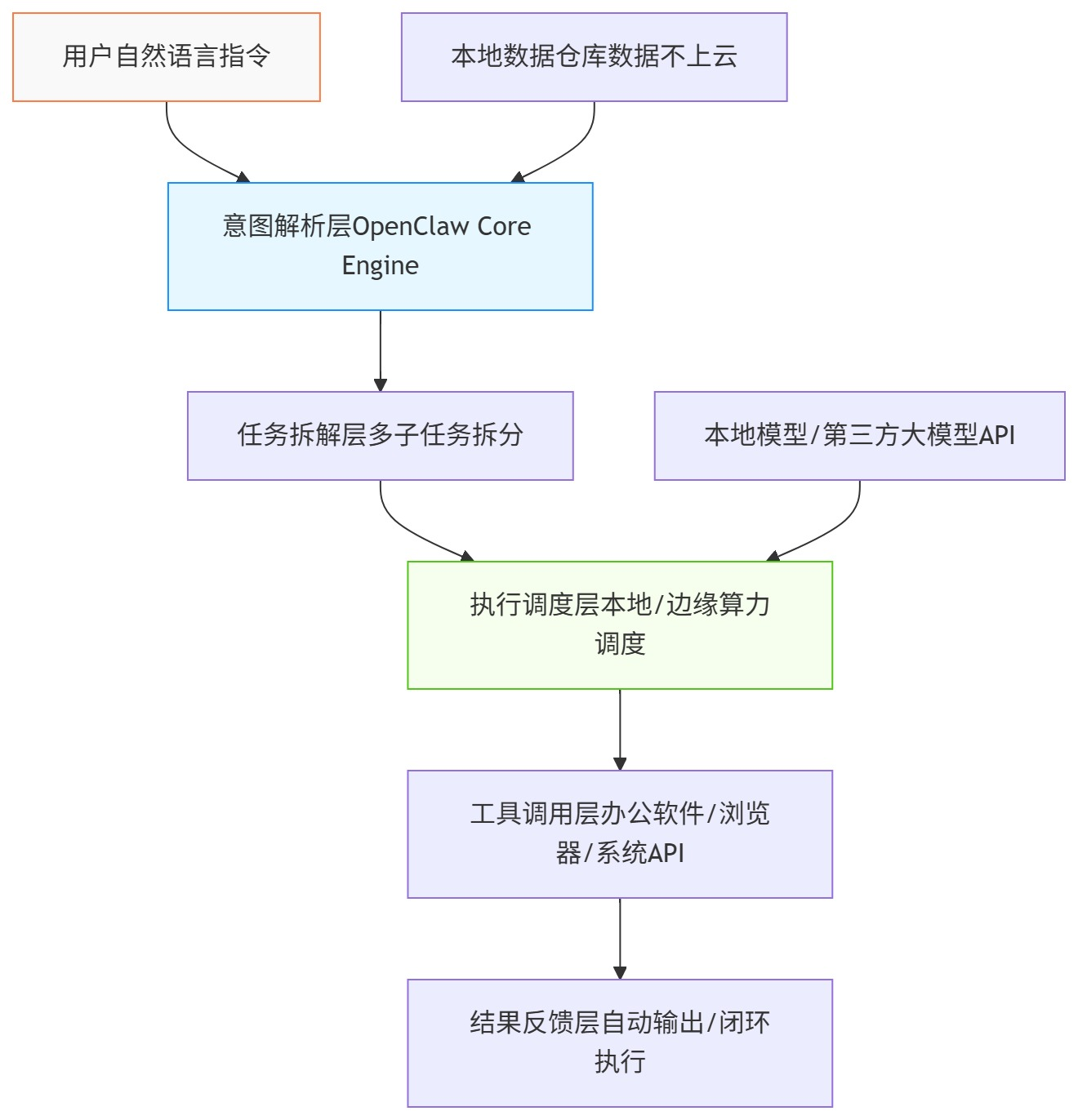
【TextIn大模型加速器+火山引擎】打破家校次元壁,基于 TextIn + Coze 打造智能批改Agent
前言:当遗忘知识的家长想辅导孩子却请不起家教,当身心俱疲的老师遇到堆积如山的作业
上周六晚上,小姨带着初二的表弟来家里做客。饭还没吃完,作业就已经摊了一桌。她一边翻着英语和数学练习册,一边苦笑着说:“现在的题我是真的看不懂了,不是不想教,是完全不知道从哪儿教。”我凑过去看了一眼——函数、几何证明、完型填空。对一个多年未碰过课本的家长来说,这些内容早已不是“忘了”,而是彻底脱节。小姨不是不努力,她陪写作业、查资料、刷短视频讲解,可越努力越焦虑;孩子不是不认真,题做了一遍又一遍,错因却始终没人真正讲清。她也想过请家教。但现实是残酷的:一对一动辄几千块一个月,质量参差不齐,效果全凭运气。很多家庭被卡在一个尴尬的位置——想要更好的辅导,却负担不起长期的专业支持。
而站在另一端的老师,其实同样疲惫。作业越布置越多,批改时间却被不断压缩;红笔改满整页,学生依旧在同样的地方出错。老师想“因材施教”,却被海量重复劳动拖住;家长想“参与教育”,却被知识门槛挡在门外。这一刻你会发现,问题并不在某一个人身上,而在于:
家校之间,存在一道越来越厚的“辅导次元壁”。
家长:有责任心,但没有专业能力
学生:有作业反馈,但没有真正理解
老师:有专业判断,却没有足够时间
当“会不会教”变成一种稀缺资源,教育焦虑就不再是个别现象,而是一种结构性困境。我忽然意识到,AI发展这么多年了,似乎并未真正的步入为所有学生服务的领域,动不动就是学习机、智能单词笔等,动辄上千块。都在说要让AI让孩子更快速学习知识,但现实却是把AI附属于那些昂贵的智能学习用品上,公司最初的为社会承担责任也转变为了利益至上。
于是我想,如果有一个工具,它仅仅是一个APP ,能够看懂孩子拍照上传的手写作业,可以自动识别题型和错误,能像老师一样指出孩子的错误并根据孩子水平动态给出专项练习。是不是能解决家长只是“陪在旁边焦虑”?老师只是在“重复劳动”中消耗?
基于这个思考,我开始尝试用 TextIn + Coze,搭建一个面向家校场景的智能批改 Agent。
业务场景
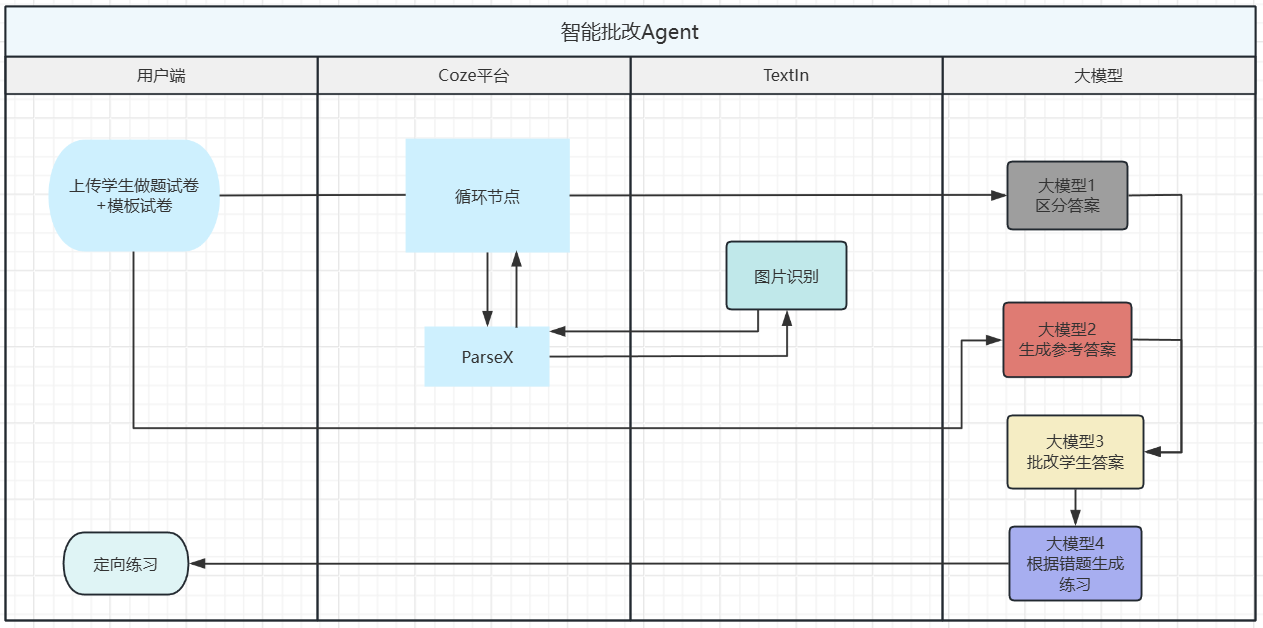
这张泳道图描述的并不是一个“批改功能”,而是一条完整的文档流转链路。流程从用户端开始,学生完成作业后,系统同时接收两份输入:一份是拍照上传的学生做题试卷,另一份是对应的模板试卷。前者承载的是高度非结构化的手写答案与解题过程,后者提供的是稳定的题目结构和题号边界。这种双输入的设计,保证了后续系统在处理学生答案时,始终有一个明确的题目参照系,而不是在一张模糊图片里反向“猜题”。
作业进入系统后,并没有立刻进入大模型推理,而是先经过 TextIn 的图片识别能力,将纸面作业转换为可计算的中间表示。识别阶段不仅输出文字结果,还会保留题块、步骤和数学表达式的结构信息,使得每一道题在系统中都有清晰的边界。这一步完成之后,作业才第一次从“人能看懂的图片”,变成“机器能理解的数据”。随后,结构化结果被送入 Coze 平台,由 Agent 的流程编排能力接管。ParseX 节点负责把模板试卷与学生试卷统一到同一套题目 schema 中,解决题号对齐和内容归一的问题;循环节点则以“单题”为粒度驱动后续流程,使每一道题都可以独立进入判题、批改和反馈阶段,而不影响整张试卷的稳定性。
在这一基础之上,大模型 开始介入,但并不是以一次性生成的方式工作。泳道图中将推理过程拆成多个阶段:先判断题型和答案形态,再生成参考解答,随后对学生解题过程进行逐步比对,最后基于错误类型生成针对性的练习内容。每一个阶段都有明确的输入和输出,使得批改结果可追溯、可调试,也避免了单次大模型调用带来的不确定性。最终,这些结果被重新汇总并写回到用户侧的学习系统中,学生看到的不只是对错判断,而是包含错误定位和后续练习建议的结构化反馈,从而形成一次可闭环的学习流程。
技术底层:为什么是TextIn+Coze+大模型工作流组合?
TextIn大模型加速器 :学生作答的精准识别高手
如果说普通 OCR 是 “看懂文字”,TextIn 则是 “读懂学生的解题逻辑”—— 作为学生作答内容的专属识别引擎,它凭借针对教育场景的深度优化,成为精准捕捉手写作业核心信息的 “高手”,其能力不止于文字提取,更在于对学生作答习惯、解题过程的全方位适配与精准还原。
学生作答的核心价值不仅在最终答案,更在解题步骤中暴露的思维轨迹 —— 这也是老师批改、系统判错的关键依据。TextIn 突破传统 OCR “逐行提取” 的局限,通过空间布局分析与语义关联识别,自动还原步骤的层级与逻辑顺序:无论是分点罗列的证明过程、分步计算的算术题,还是带有箭头指引的推导步骤,都能被拆分为 “步骤 1 - 步骤 2 - 步骤 n” 的结构化数据,且保留每一步与题干、公式的关联关系。即使学生字迹密集、步骤交叉书写,TextIn 也能通过上下文语义与空间位置校准,精准区分不同步骤的边界,避免因步骤混淆导致后续判题误判,真正实现 “机器能读懂的解题逻辑”。
Coze+大模型:智能批改的 “逻辑中枢” 与 “推理大脑”
Coze 与大模型的组合,彻底解决了 “流程不可控” 与 “推理不精准” 的双重痛点:Coze 通过模块化编排,让大模型的推理过程 “有章可循”,避免了单次调用带来的结果不确定性;而大模型的深度推理能力,又让 Coze 的流程编排 “有血有肉”,摆脱了传统规则引擎的僵化局限。两者组合,仅通过拖拽、点选等简单操作,就能快速将 TextIn 的解析能力与大模型的交互功能串联起来。例如,当学生解题步骤不完整时,Coze 会驱动大模型先判断 “是遗漏关键步骤” 还是 “步骤表述简洁但逻辑完整”,再决定是否标记错误;当大模型生成的练习难度过高时,Coze 会调用学生历史学习数据接口,动态调整练习难度,确保推荐内容的适配性。这种协同让整个批改流程既 “稳定可靠” 又 “智能灵活”,完美承接家校场景的核心需求。
技术方案:15 分钟搭建全自动批改Agent
搭建流程
接下来我们开始搭建Coze工作流,可以分为以下三步:
Coze工作流创建:拖拽节点,添加"TextIn文档解析"插件
大模型交互配置:接入选择好的大模型以及工具,设置prompt(对文档进行什么处理,输入时什么,输出是什么等)
确定输出格式:要求模型输出url链接方便用户下载,最终可以回写入APP里(此步过于庞大,未实现)。
首先我们点击Coze创建工作流,然后进行直观的工作流描述,这样如果后面有搭建Agent智能体的需求,可以让智能体知道在什么场景下调用该工作流。
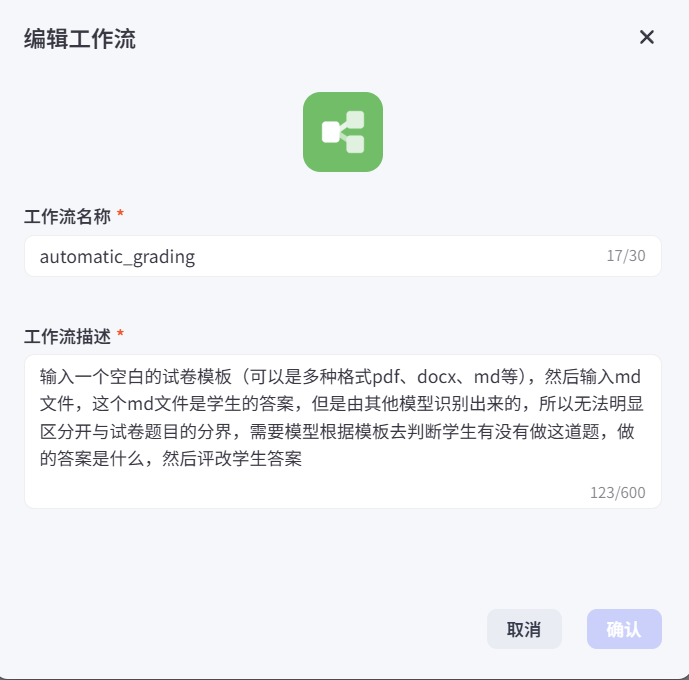
我们将集成合合信息专为 LLM 下游任务打造的 TextIn ParseX 解析插件 —— 作为聚焦智能文档解析处理的核心组件,它是整个 Coze 工作流的关键环节。该插件可精准识别文档或图片中的文字信息,将内容转化为 Markdown 格式,并严格遵循常规阅读顺序完成内容还原,既能保证文档结构与信息的完整性,又能为下游各类大语言模型任务(如内容分析、问答生成、知识提取等)提供高质量的数据支撑,有效赋能 LLM 下游任务的落地执行。并将其插入循环节点中,确保每次上传的图片数量不一样,都可以遍历解析完。
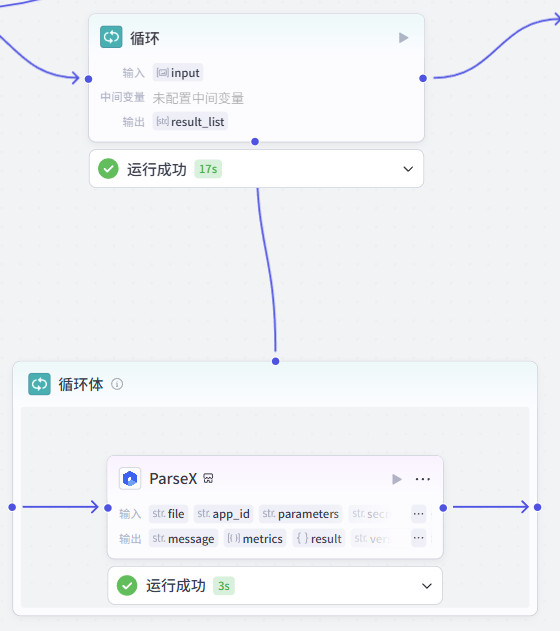
然后添加大模型节点,如图所示,配置好对应的输入、提示词、用户提示词即可。
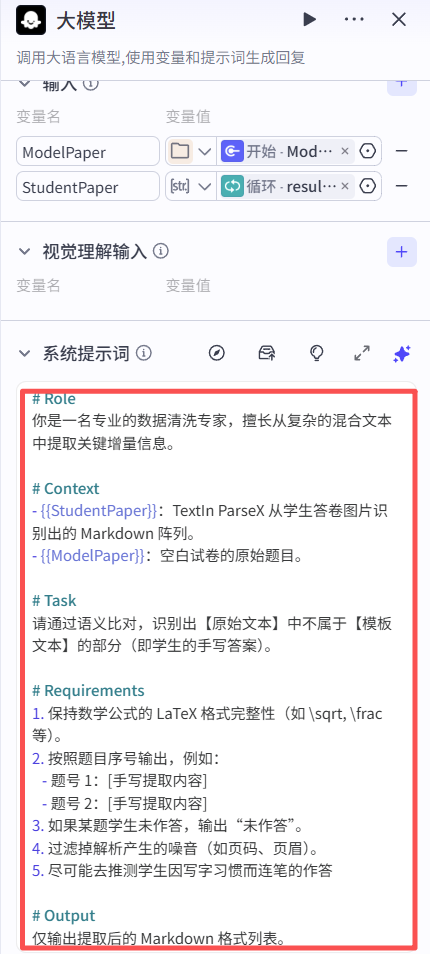
将所有大模型prompt进行配置后,我们的工作流即可创建完成,不需要涉及任何第三方的密钥,十分的快捷且方便。效果如下所示:
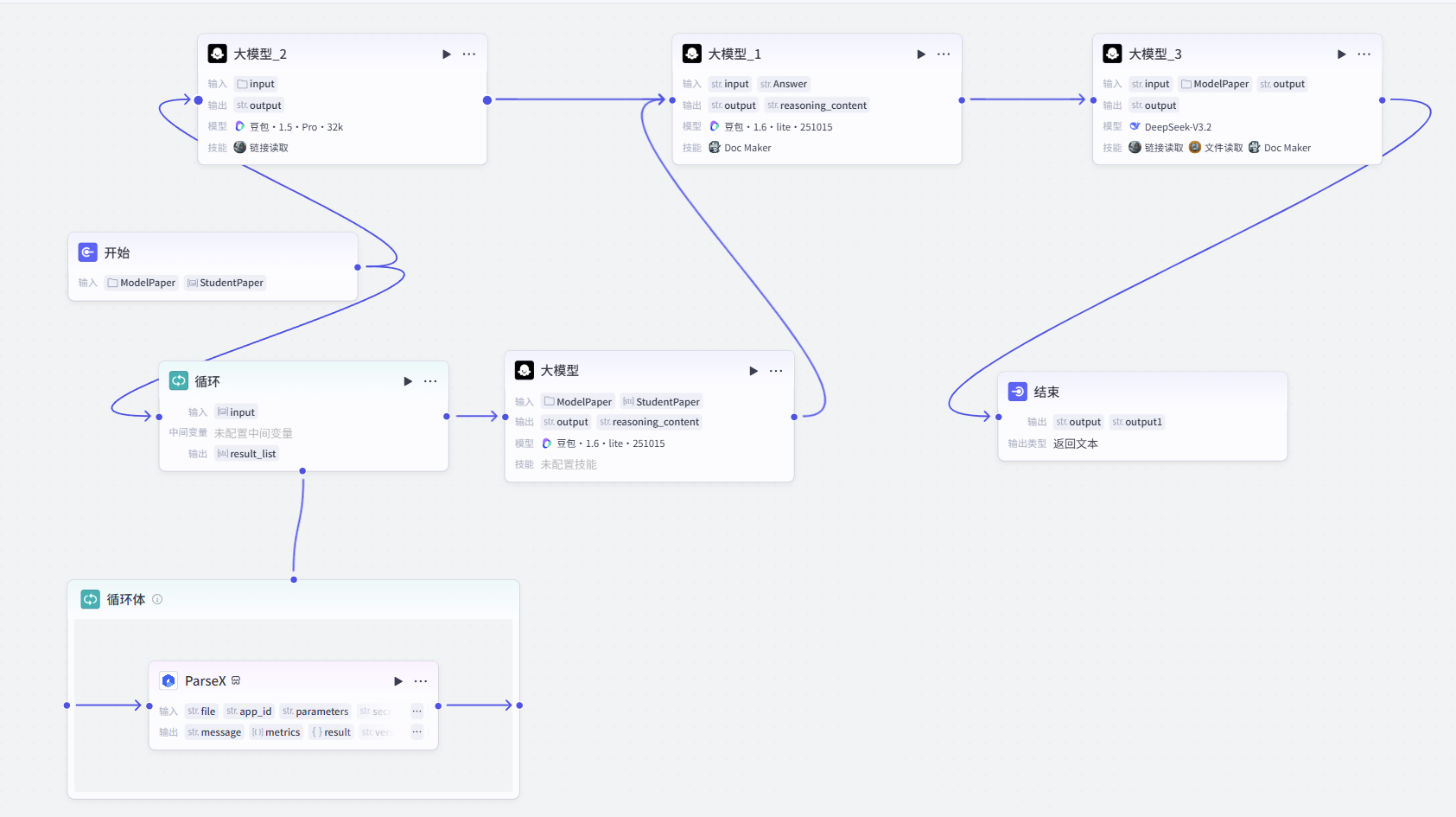
测试与对比
这里我选择了一套初三英语试卷作为工作流测试对象,选取该试卷的 8 张拍摄照片作为输入测试,能从场景覆盖、功能验证、实用性三个维度充分检验工作流的可靠性,具体可以概括如下:
覆盖了初三英语试卷的典型复杂格式,验证 ParseX 适配性:
多元素排版适配:包含选择题、完形填空、阅读理解、书面表达等题型布局,还有中英双语题干(英文题目 +中文说明)、题号层级、选项列表、表格类阅读素材、手写印刷体混排(如题目标注)等英语试卷常见元素,能测试 TextIn对复杂排版的解析精度;
多信息模块覆盖:同时包含题目文本、选项内容、分值标注、答题区域、题型分类标识等工作流需提取的全量字段,可一次性验证所有目标字段的提取完整性。
验证工作流的核心能力与完整流程:
OCR 解析能力测试:8 张照片涵盖不同题型的印刷体文本、中英文混排、特殊标点(引号、破折号、括号)、数字序号等,能检验 TextIn对英语学科文本的字符识别准确率(避免乱码、错字、漏识别选项);
结构化提取能力验证:可验证大模型节点是否能准确区分 “题干 / 选项”“不同题型文本”“分值 / 题号”
等同类字段,避免信息混淆或字段归属错误;
端到端流程完整性:从 8 张试卷照片依次解析→分题型字段提取→结构化结果输出的全链路流程,能验证 Coze工作流的插件串联、多图片批量处理、数据跨节点传递是否无断点。
贴合实际应用场景,验证工作流实用性:
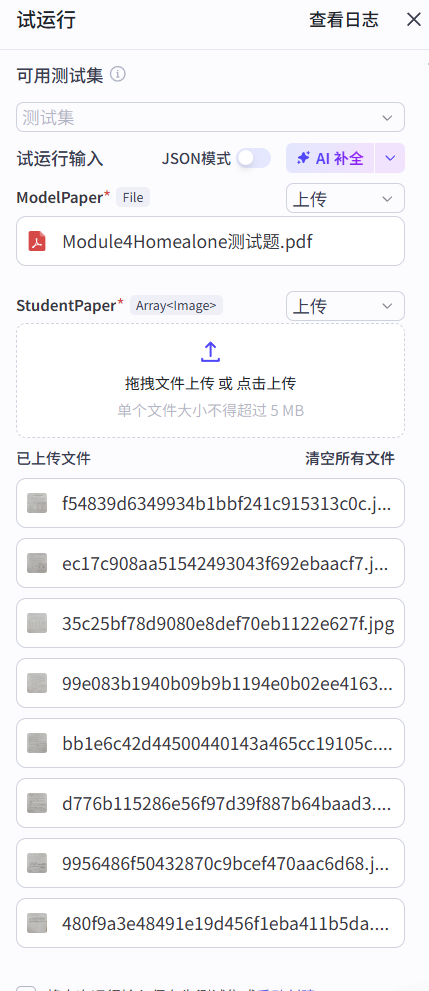
真实教学场景匹配:初三英语试卷是课外辅导、学情分析的高频处理对象,以此为测试样本,能验证工作流在实际教育场景中批量处理试卷文档的可用性;
多图片拼接适配:8 张照片对应试卷不同页面,可测试 ParseX对多页文档的连续解析能力,以及工作流对分片图片的整合处理效果,贴合真实场景中 “整卷分拍上传” 的使用习惯。
最终用时4分20秒,当然,这并不算好,原因是我们调用了太多不同的大模型,但如果能使用强大模型,我相信一个模型就足以代替这4个模型的工作。
我们打开输出的两个url链接进行查看,模型的输出是达到了我们预期的目标的:
真人对比
我们参考正确答案,找了一位英语老师进行对比,以及让一个初三孩子家庭对工作流效果进行评价,得出了如下信息:
对象 准确率 改卷时间 出题时间 家长评分(100)
Agent 86% 4分20秒 4分20秒 95
老师 100% 2分01秒 43分53秒 96
我们可以看到,基于 TextIn + Coze 打造智能批改Agent虽然在准确率上比不上真人,但它在时间开销上是远远胜过真人老师,如果一个班上有几十名学生,老师是无法做到针对每个学生的错题进行出题专项练习巩固知识的。而家长更难以做到为自己的孩子改题目出练习,而我们仅花费15分钟就搭建好了一个解决两边难题的工作流。
总结
受限于项目推进的时间周期与现有资源投入,我们暂未开发专门的 APP 来承载和展示最终的回写内容,现阶段主要通过基础输出界面完成结果呈现。同时,由于当前工作流中集成了四个不同功能的模型协同运作,多模型的调用、数据交互与结果整合环节不可避免地增加了整体耗时,导致输出效率尚未达到最优状态。但结合技术验证过程中的经验来看,若替换为两个功能更强大、适配性更高的核心模型,通过精简模型链路、优化数据传递逻辑,我们完全有信心对这一工作流进行更高效的迭代升级 —— 不仅能显著缩短处理耗时,还能进一步精简流程节点、提升结果精准度,实现整体效能的跃升。
TextIn 与 Coze 搭建的这套工作流,让我切实看到了 AI 技术真正落地教育场景的清晰路径与巨大潜力:它打破了传统教育中优质辅导资源的壁垒,无需复杂的技术门槛,无论是身处城市还是乡村的家庭,无论是经验丰富的资深教师还是刚入行的年轻教育工作者,都能借助这套智能化工具,为孩子提供个性化的学习辅助 ——从试卷解析、错题分析到针对性训练题生成,AI 能精准补足人工辅导中的效率短板与细节盲区。这意味着,AI 不再是教育领域的 “概念化存在”,而是真正能触达每一个家庭、每一位教育者的实用工具,让普惠化的优质教育辅导成为可能,也让我们对 AI 赋能教育的未来充满期待。
- 本文标签: 大模型 开源
- 本文链接: https://www.cloudbs.top/article/4
- 版权声明: 本文由TTL原创发布,转载请遵循《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权