VLM vs YOLO,谁才是未来?当"会看图的大模型"遇上目标检测
前言
如果你关注过目标检测,大概率听过"YOLO"——这个速度快、效果稳的经典框架,几乎是工业界的"标配"。
但最近,一种新势力正在崛起:VLM(视觉语言大模型)。它不仅能"看图说话",且也能进行目标检测。
今天这篇,就用大白话讲清楚其原理、对比优劣,还送你一个能立刻上手的体验工具👇
模型结构差异
VLM(视觉大模型)与YOLO模型结构最大的区别在于:
VLM是基于transformer架构,而YOLO模型是基于CNN结构(即卷积神经网络架构)
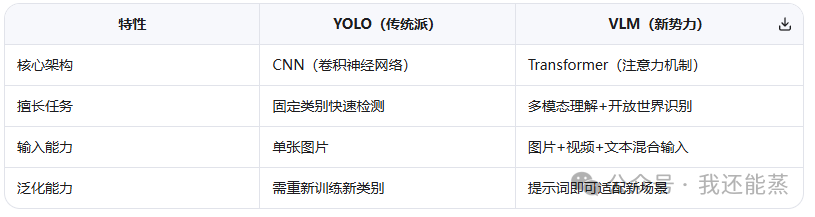
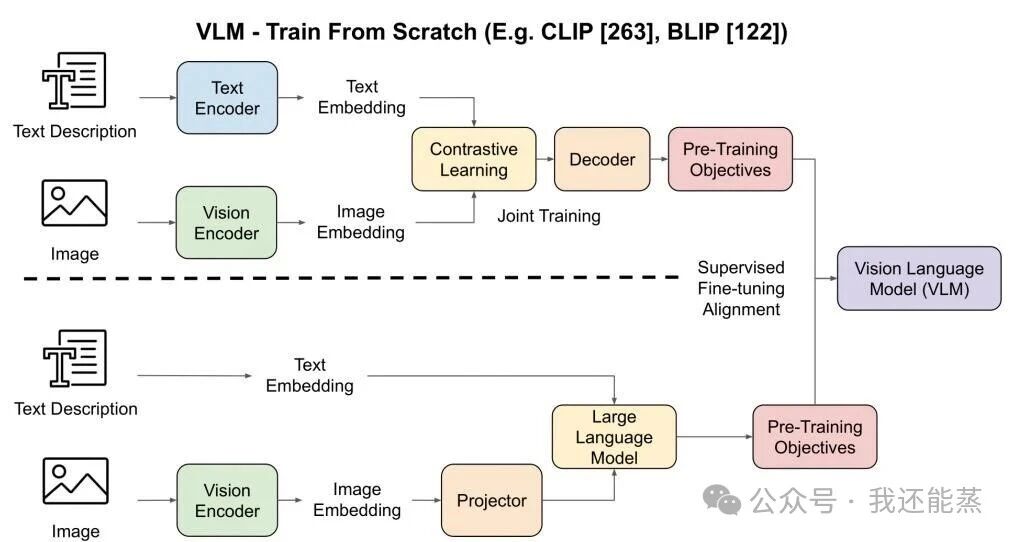
在视觉领域上,目前这个两个架构,哪个更好,还有比较多的争议,根据目前的榜单和信息,一个比较公认的事实是transformer结构视觉头具有更多潜力,直接证据就是目前VLM模型不仅能输入图片、还能输入视频
同时最近发布的Qwen3.5系列,大家关注比较多还是林老师离职阿里,但是如果认真Qwen3.5系列模型,会发现全是VLM模型,一个文本生成模型都没有!
而回到目标检测,过去一直是YOLO的天下,而VLM的面世后,主要也是用来进行图像生成描述性文本(图像描述)、回答基于图像的问题(视觉问答),很少有人进行拿VLM进行目标检测,但实际上VLM也是可以对进行目标检测
但是目前的VLM目标检测,很多案例还是用来检测猫、狗之类的,我认为这完全没有发挥VLM的泛化能力
举个例子,场景是在施工现场,我使用yolo目标检测,能检测图片中工人是否佩戴安全帽

而使用vlm进行目标检测,不仅能检测工人是否佩戴安全帽,还能检测出施工现场的其他安全问题,如常见临边防护、垃圾堆放

通俗理解:
- YOLO 像"专业质检员":训练时学了100种零件,就只能认这100种,但识别又快又准;
- VLM 像"聪明实习生":没专门学过,但靠常识+描述,能猜出"那个戴红帽子没系安全带的工人"有问题。
VLM目标检测原理
VLM 怎么做目标检测?关键就一句话:会写提示词
我们只需要在提示词中命令模型输出边界框坐标和隐患描述,并要求以JSON格式返回
你告诉它要看什么、怎么输出,它就直接给你结果。
同时举上述工地安全隐患的列子:
**角色**:你是一名工地驻场安全员。**目标(一步一步执行)**:1. 识别图像中所有安全隐患2. 为每个安全隐患标注其2D边界框坐标3. 用中文描述这些安全隐患**要求**:1. 坐标格式为 [x1, y1, x2, y2]2. 输出格式:JSON**json格式案列**:[{"bbox_2d": [120, 85, 340, 290],"label": 对应的隐患描述},{"bbox_2d": [450, 210, 620, 500],"label": 对应的隐患描述}]
当然,模型直接输出的边界框坐标,是无法直接使用,还需要进行归一化处理,具体处理过程大家可以参考我的开源项目:https://github.com/xiaohuangpin/SecureEye
因此我认为,VLM目标检测也有不少的应用空间,如检测厨房后厨卫生、治安管理、行业特定目标检测(如医疗影像、交通监控等)
✅ **真正该用它的地方**:
| 场景 | YOLO 的局限 | VLM 的优势 |
|------|-------------|-----------|
| 🏗️ 工地安全 | 只能检测预设类别(如安全帽) | 能理解"脚手架松动""材料乱堆"等复杂隐患 |
| 🍳 后厨卫生 | 需大量标注"口罩/帽子/生熟混放" | 用自然语言描述规则,模型自动推理 |
| 🚦 交通管理 | 固定检测车辆/行人 | 可识别"违规停车+占用消防通道+人群聚集"组合风险 |
| 🏥 医疗影像 | 每类病灶需单独训练 | 结合文本描述,辅助定位+解释异常区域 |
同时我做了一个线上小应用,为帮助大家快速原型验证与演示,该应用已经上线魔搭社区的创空间

对应网址:https://www.modelscope.cn/studios/Miyabe/vlm_cv_playground/summary
创空间使用教程视频:https://www.bilibili.com/video/BV1Lcw4zsEWw/?spm_id_from=333.1387.homepage.video_card.click
这个应用写好图片处理代码,各位可以在这里编辑提示词,对你想法进行快速原型验证与演示
至于模型,本人没什么名气,没能拿到大厂的支持或者赞助,因此大家可以去智谱官网注册一个账号,智谱官方提供免费的VLM大模型,本人推荐GLM-4.6V
优劣对比
上面讲了怎么多的VLM的优势,但实际发现还是YOLO在行业内应用多,这主要是因为YOLO的发展十分成熟,目前YOLO能在cpu跑出很低延迟,基本能做到实时处理,而vlm目前都是跑在GPU上,而且基本也要十秒左右才能处理好
同时YOLO对于固定类别的识别有很高的正确率,而VLM的泛化能力强了,却带来了正确率下降,对于特定行业领域,可能还需要特定数据集微调才能达到更好的效果